Proprietary SEO Tools
These tools are proprietary and used exclusively on client engagements — not shipped as products. Summaries of what each one does:
Taxonomy Tool
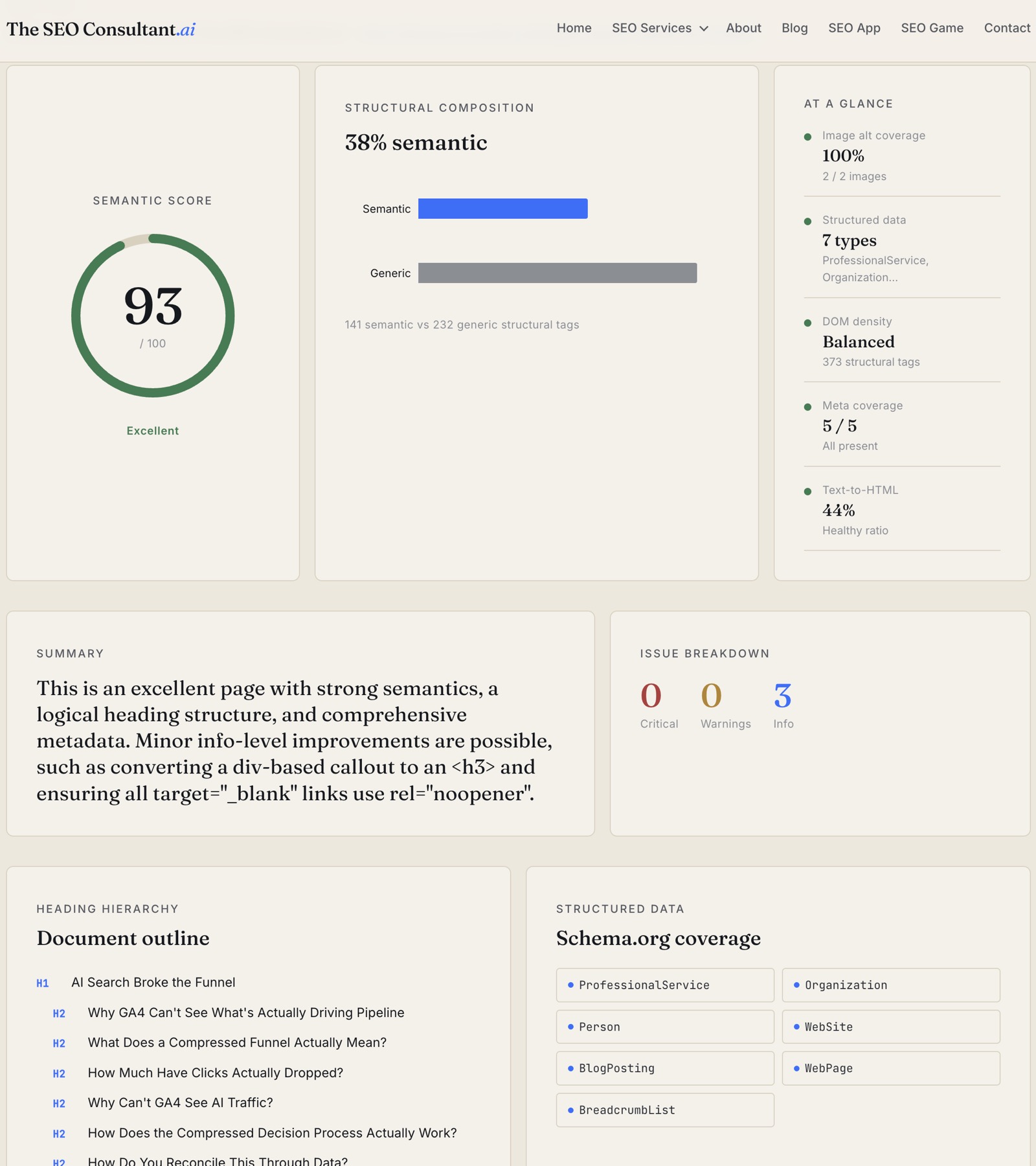
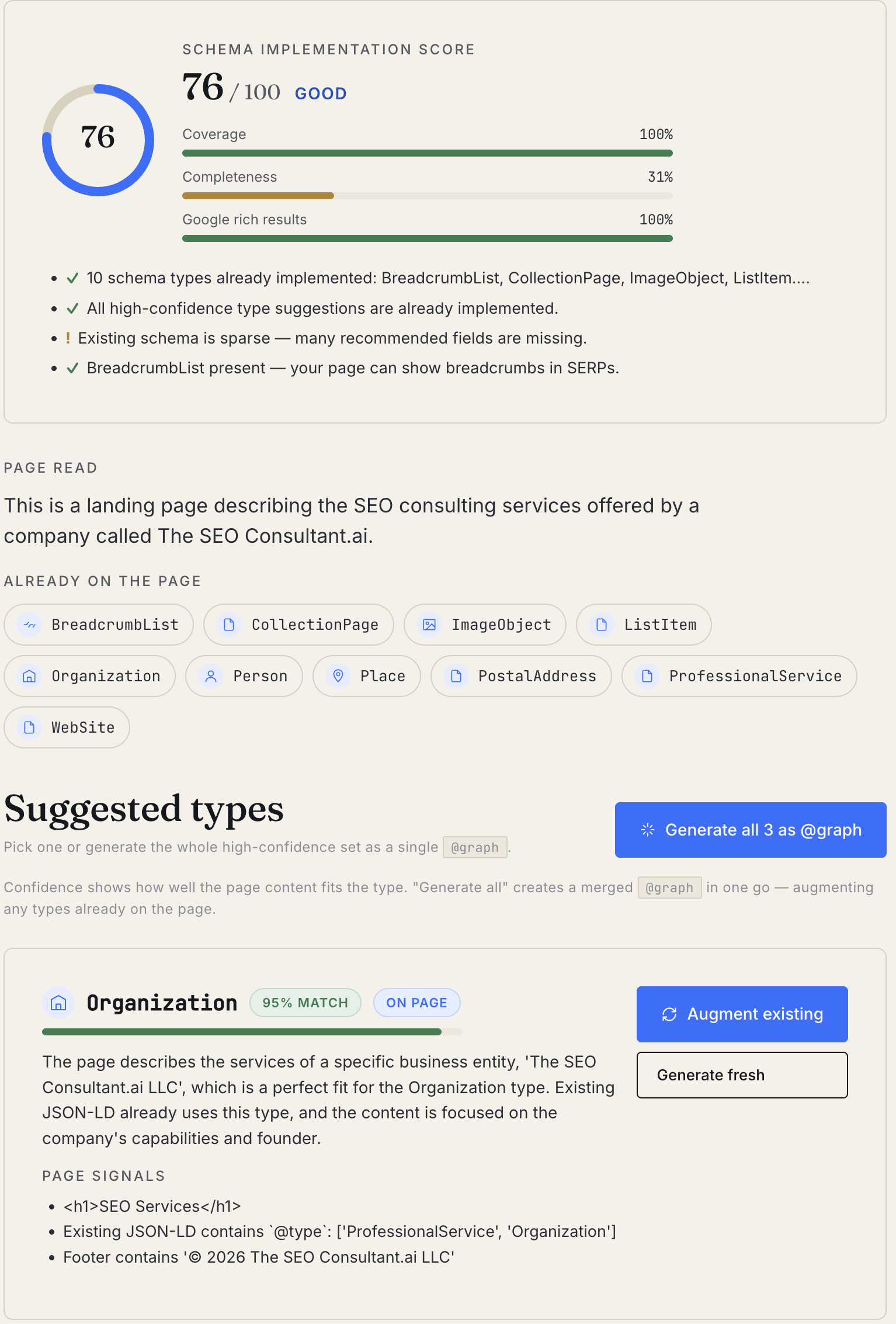
A Next.js and TypeScript application that generates hierarchical e-commerce taxonomies from real site data. It ingests Screaming Frog crawls, Google Search Console queries, GA4 sessions, and Semrush keyword data, then uses Gemini to produce a category tree with meta titles, slugs, and JSON-LD BreadcrumbList markup — scoped to defined customer personas and ready for CMS integration.
AI Search Simulator
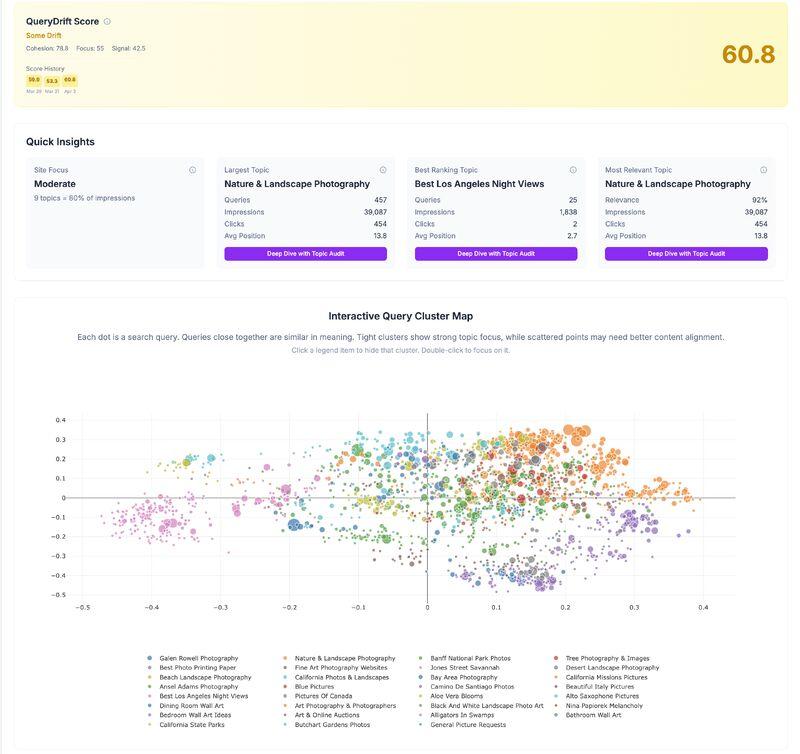
A Streamlit application that loads a site, or competitor sites, into a Qdrant vector database using EmbeddingGemma or Gemini embeddings. Once indexed, the collection can be queried the way an AI retrieval system would, content gap audits can be run against a sitemap, and internal-linking suggestions can be generated across the full embedding space. Scraping is handled via Zyte; entity detection via Google Cloud Natural Language.
Media Mix Modeling
A custom Bayesian Media Mix Modeling application, built in-house on similar principles to Google Meridian rather than on top of it. Users upload weekly or daily media spend and revenue, select their channels (paid search, paid social, display, video, affiliate), and the model returns channel attribution with credible intervals, diminishing-returns response curves, budget-allocation optimization, and what-if scenario planning. Designed for the conversation that starts with defending a marketing budget in front of a CFO.
Entity Gap Analysis
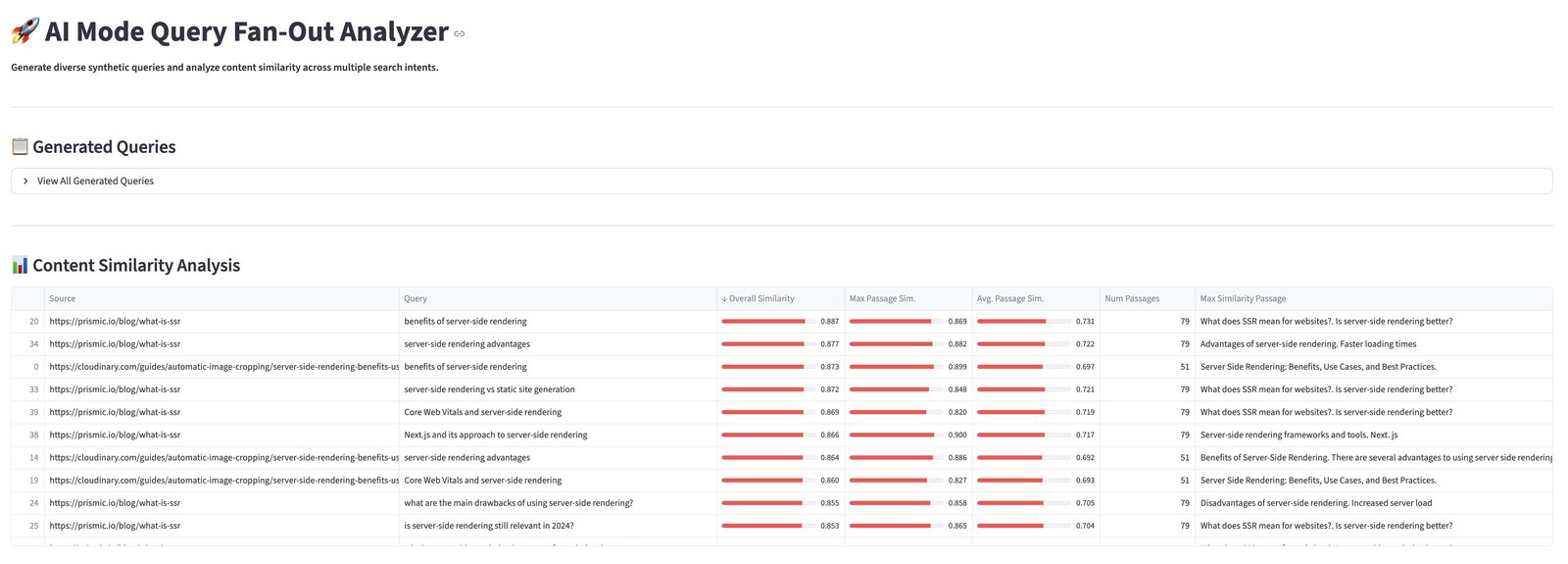
A Streamlit tool that extracts entities from both client content and competitor content using Google Cloud Natural Language, scores them against target queries, and renders a relationship graph via networkx. The output: a ranked list of entities competitors are using that the client is not — weighted by query relevance. The result feeds directly into content strategy decisions.
Working With Me on These
The Semantic HTML Analyzer, Schema Markup Generator, and Fan-Out Analyzer are free to use. QueryDrift has a free tier. The harder part is interpreting the scores and refactoring the markup — or shipping the right schema, or writing the passages — that close the gaps. That's what the AI SEO consulting service is for. If you want me to run these against your site and return a punch list, start a conversation.